QGISで「編集モードにならない」「地物が選択できない」とき
QGISver.3.24.3を利用しています。先日、関東地方の国土数値情報をダウンロードして編集しようと思いました。具体的には離島については自然環境が違いすぎるので、以降の解析から除くためでした。しかし、なぜか東京都と神奈川県のシェイプファイルだけ編集モードになりません。ググってみると、「編集モードにならない」という現象はたまにあるようです。仕方ないので、東京と神奈川だけ、次のようにいったん「エクスポート」⇒「新規ファイルに地物を保存」として保存しなおしてみました。
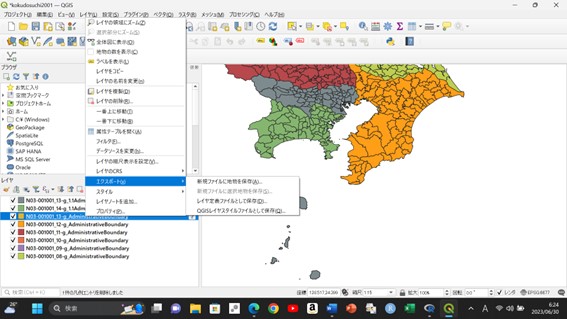
これで再度読み込みなおすと「編集モード」になりました。「めでたし、めでたし」と編集しようとすると、パネルにある地物選択ツールから離島が選択できません。東京都から離島をはずしてはならないという行政的配慮でしょうか?。個人的には強く同意しますが、まだイノシシが分布していないので、解析をするときにこれら離島は除いておきたかったのです。そこで属性テーブルを開いて、地物を選択してみると…選択できました。そこでもう一度パネルモードに戻ってみると…選択できました。なぜかはわかりませんが、今度こそ「めでたし、めでたし」です。
Rで地域メッシュコードから緯度経度をまとめて取得
久しぶりの更新です。地域メッシュコードが膨大に入っているCSVファイルから、それぞれメッシュ中心の緯度経度に変換したいと思いました。Rのjpmeshパッケージで変換は可能とわかりました(作成者の方、どうもありがとうございます!)。
標準地域メッシュを扱うRパッケージを更新しました: jpmesh v.1.0.0 - cucumber flesh
作業内容は知っている人にとっては当たり前のことなのですが、初心者には悩むところがあったので、アップしておきます。(パッケージの中身よりも、Rを扱う私の知識不足による問題ですね!)
Rはversion4.2.2を使いました。library(jpmesh)の読み込みまでは割愛させていただきます。まずは地域メッシュ(メッシュコード)の含まれているCSVファイルの読み込みです。
> d<-read.csv(file.choose(),header=T)
と入力するとファイルを選択できます。header=Tは、第1行はヘッダであると指定するためのものです。読み込んだデータの確認をするのに膨大な行数が含まれている場合はhead関数を使うと最初のほうだけ確認できます。このデータはメッシュごとに動物の確認回数が含まれているもので、Numberの列がその回数です。
> head(d)
Mesh Number
1 362335 2
2 362336 3
3 362337 2
4 362345 2
5 362346 4
6 362347 3
このうち、1列目のメッシュコードだけを処理すればよいので、1列目のデータのみを抽出します。このデータセットはd2にします。headで中身を念のため確認しておきます。
> d2<-d$Mesh
> head(d2)
[1] 362335 362336 362337 362345 362346 362347
ここでjpmeshパッケージの関数mesh_to_coordsを使います。メッシュから緯度経度に変換してくれる関数です。
> d3<-mesh_to_coords(d2)
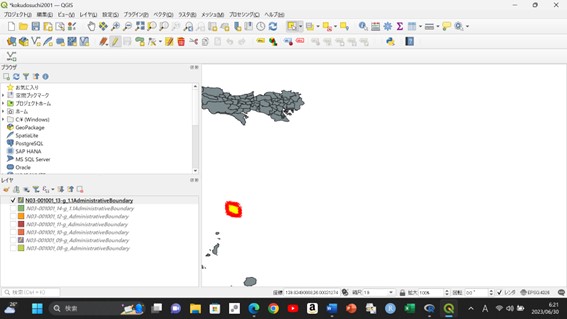
> head(d3)
# A tibble: 6 × 5
meshcode lng_center lat_center lng_error lat_error
<meshcode> <dbl> <dbl> <dbl> <dbl>
1 362335 124. 24.3 0.0625 0.0417
2 362336 124. 24.3 0.0625 0.0417
3 362337 124. 24.3 0.0625 0.0417
4 362345 124. 24.4 0.0625 0.0417
5 362346 124. 24.4 0.0625 0.0417
6 362347 124. 24.4 0.0625 0.0417
中身は上記のようになっています。 lng_center のところにある「124.」というのがメッシュ中心の経度、lat_center のところにある「24.3」というのがメッシュ中心の緯度です。そのあとはそれぞれの誤差のようですが、今回は緯度経度の値のみで処理しました。上記のようになっているので、たとえば経度の小数点以下はどこに出てくるのかしばらく悩んでいました。あとでCSVに書き出したらきちんと小数点以下のデータも含まれていました。折りたたまれているだけなのでした!たとえば、d4というデータセットでd3のうち「lng_center」つまり経度の中心だけ抽出してみます。
> d4<-d3$lng_center
> head(d4)
[1] 123.6875 123.8125 123.9375 123.6875 123.8125 123.9375
上記のようにちゃんとそれぞれ変換されていました。抽出したデータをまとめてCSVファイルに出力します。
> write.csv(x = d4, file = "exportdata.csv")
このようにするとexportdata.csvというファイル名でデータセットd4が保存されます。
2列まとめてのときは
>d4<-data.frame(x=d3$lng_center,y=d3$lat_center)
>write.csv(d4, file = "exportdata.csv")
とします。
保存先は作業しているディレクトリなのですが、どこだかよくわからない場合はまずは上記のように保存してしまい、あとで次のように入力すると場所がわかります。
> getwd()
[1] "C:/Users/ここにユーザー名など/Documents"
下記のように無事、CSVファイルができました。
うつりゆくQGISで地質図をつくる
3年以上ほったらかしていたブログですが、久しぶりにQGISを使ったので、備忘のため記録を残しておきます。私がQGISを使い始めたころはバージョン1.8とかでしたが、すでに3.16(最新版はさらに3.2とか)になっていたのですね。久しぶりに使ってみると細部が変わっていて、戸惑いつつもやはり全体としては大きく進歩していました。
今回は知床周辺の地質図作成をしました。産総研の提供している地質図を利用します。こうして地質図のデータも気軽に利用できるようにしていただいて、本当に感謝です。今回は20万分の1を使っています。
用途にあわせてshp形式、またはgeotiff形式を選べます。
新規プロジェクトを立ち上げて保存→その後、プロジェクト>プロパティ>座標参照系のタブを開いて、CRSを設定します。元データはJGD2000に準拠していますが、平面直角座標系にするには下記を参照して、JGD2000/Japan Plane Rectanglar CS (数字)という形式にしなければなりません。JGD2000のままだとゆがんで表示されます。下記を参照して知床付近は13なので、
JGD2000/Japan Plane Rectanglar CS XIIIを選びます。
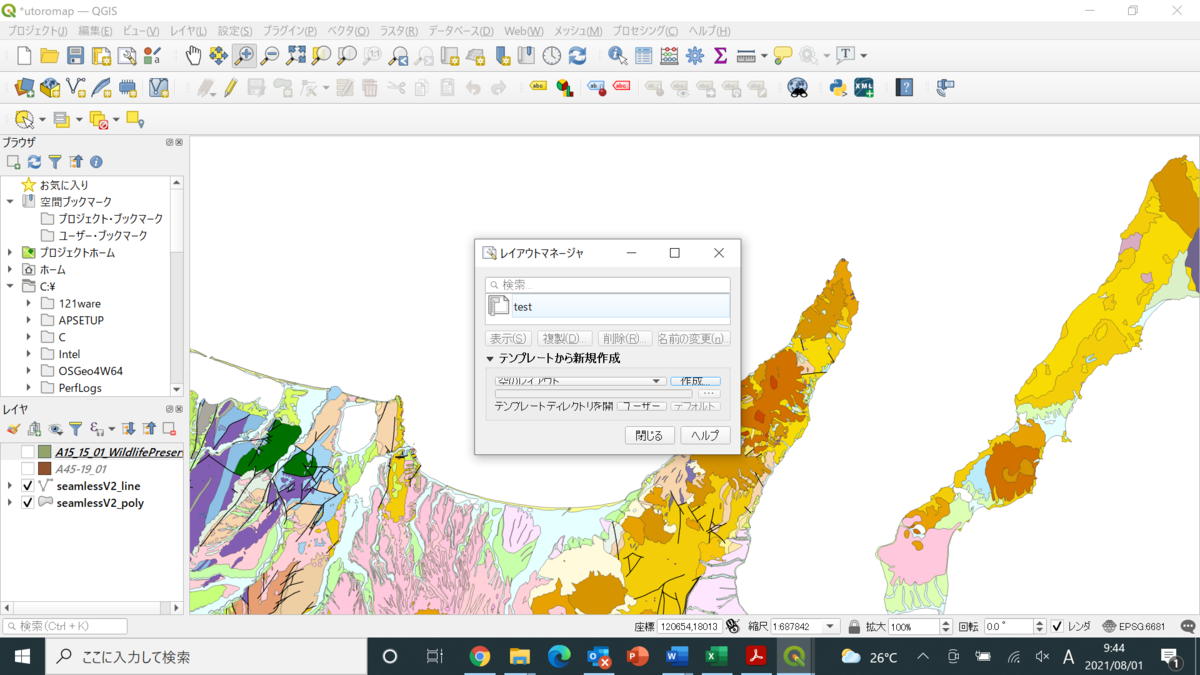
あとはこれを印刷すればよいのですが、かつてはプリントコンポーザというのを使っていました。どこにもその名前はなく、次の通りのプロセスになっていました。
プロジェクト>新規印刷レイアウト
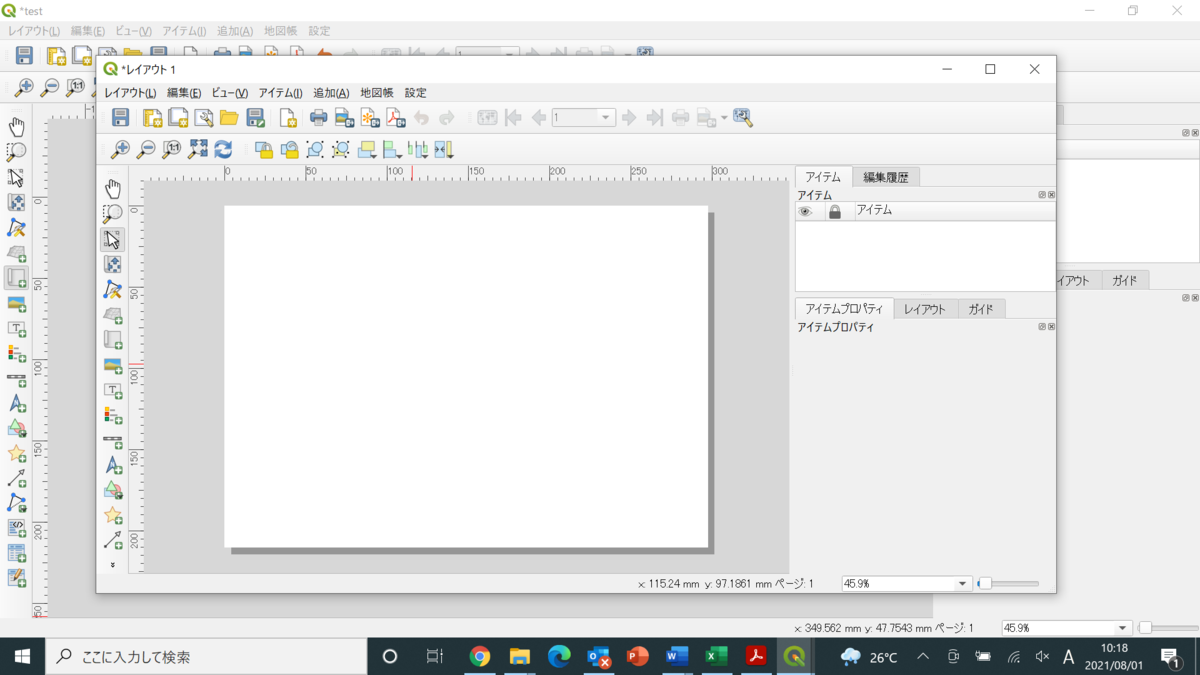
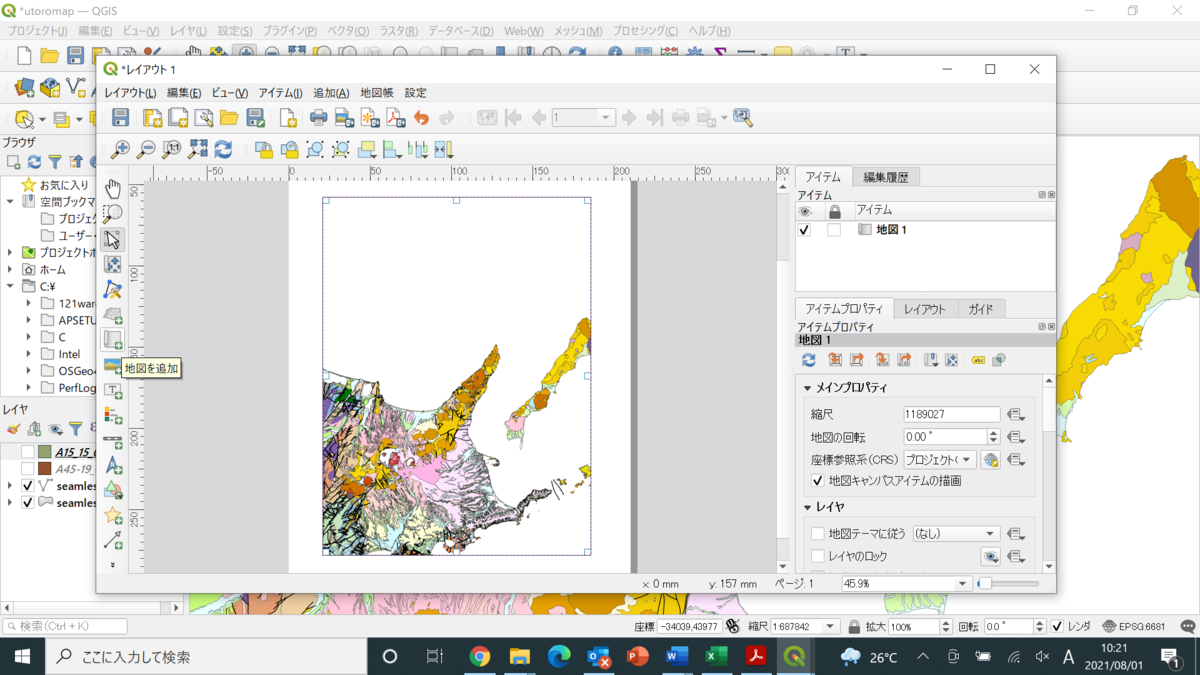
ここに地質図を表示させるのですが、その前にこれを縦長にしたいと思います。コンポーザーマネージャーもないので、しばらく悩んでましたが、画面のレイアウトの上で右クリックすると、右側にページプロパティが現れました。ここでA4縦に直しました。下図の左側にある地図を追加というアイコンをクリックして、十字のカーソルで領域を指定してやると、その中にQGISで開いていた地図がそのまま表示されます。とりあえずこれで利用できます!
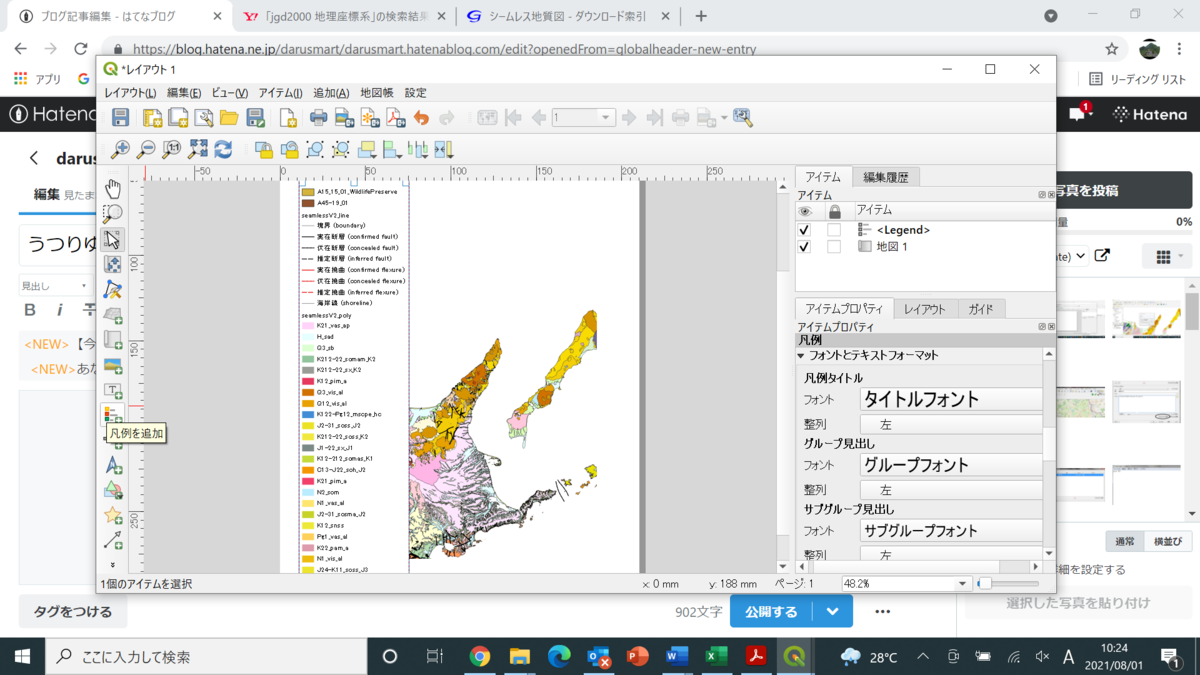
地質図には凡例が必要です。そこで、下図の場所のアイコンで凡例を追加します。偉く長いのでびっくりしました。仕方ないので、下図の右側にある凡例のアイテムを調整するところで、フォントを小さくします。
QGISで河川と道路の国土数値情報を重ねあわせる
備忘のためのメモです。参照に来た方、適当になってすみません。
1)国土交通省ウェブサイトから、国土数値情報をダウンロードします。
たいへんお世話になっているサイトです。ありがとうございます!アンケートに答えてダウンロードです。今回は海岸線、道路、河川のデータのうち北海道のものを使いました。
2)xmlファイルのものはシェイプファイルに変換。QGISにxmlをシェイプに変換するプラグインもありますが、なんだかうまくいかないことも多いです。同じ国土交通省サイトからksjツールをダウンロード(下記サイト)して使うのが確実かと思います。
3)QGISでベクタ形式ファイルとして順番に読み込む。
今回使用したデータは空間参照系がJGD2000(EPSG:4612)なので、どのファイルもそれで統一する。
4)しかし、河川ファイルは2級河川や準用河川というかなり細かい川までデータになっています。(下記)

河川データの仕様書を見ると、区間種別コードの指定がありました。属性テーブルで、たとえば1級河川だけに絞れば整理されるということですね。
<区間種別(COP)コード>
1(1級直轄区間) 2(1級指定区間) 3(2級河川区間) 4(指定区間外) 5(1級直轄区間でかつ湖沼区間を兼ねる場合) 6(1級指定区間でかつ湖沼区間を兼ねる場合) 7(2級河川区間でかつ湖沼区間を兼ねる場合) 8(指定区間外でかつ湖沼区間を兼ねる場合) 0(不明)
QGISで特定の地物をクリックすると画像が開くようにする方法
QGISはオープンソースのGISソフトとしてたいへん便利ですが、ときどき思い通りに操作できないことがあります。今回もかなり苦労しました。トライしたのは、特定の地物をクリックして画像を開くという操作です。たとえば、GPS付きのカメラで撮影した画像を地図とリンクさせられたら、とても便利です。またまた苦労を重ね、最後はコンピュータに詳しい同僚の助けをもらって次の方法にたどりつきました。
1)画像からGPS情報を抽出する。
まず、GPS情報を持っている写真の情報(EXIF)を一括して閲覧したり、エクスポートしたいと思いました。枚数が少なければ手入力でもよいですが面倒ですね。これにはExif情報を抽出するフリーウェアを利用しました。リンクを掲載してよいかどうか不明でしたのでここでは名前は伏せます。私のカメラ(Canon PowershotD30)では緯度経度が「・・度・・分・・秒」となっていたのでこれをExcel上のワークシート関数で変換しました。たとえばC2に上記の緯度がある場合、次の関数で小数点に変換できました。
=LEFT(C2,FIND("度",C2)-1)+(MID(C2,FIND("度",C2)+1,FIND("分",C2)-FIND("度",C2)-1))/60+(MID(C2,FIND("分",C2)+1,LEN(C2)-FIND("分",C2)-2))/3600
今回はヨーロッパの写真が対象で、東経と西経の両方が登場しました。区別はそれぞれプラス、マイナスとしておけば大丈夫でした。これをCSVファイルにして、QGIS(今回は2.12.0を使用。PCはwindows7です)から読み込みます。いつもどおりセルやファイル名に日本語を含めないのが無難です。このCSVファイルに画像の場所を指定する列も加えておきます(列の一部はこちらの都合で隠しています)。

QGISからのCSVファイル読み込みは「レイヤ>ベクタレイヤの追加>デリミティッドテキストレイヤの追加」です。
2)QGISのアクションとバッチファイルを利用して地物と画像のリンクをつくる。
QGISにはプロパティ(レイヤーを選択してダブルクリックすると開くメニューの中にある)を開くと、”アクション”というタブがあります。このアクションを利用すると地物と特定の動作を結びつけることができます。ところが少しクセがあるようで、いくつかのウェブサイトに書かれていた方法ではうまくいきませんでした。同じように困った方は次を試してください。
(1)バッチファイルをつくる。
次のようにテキスト入力したファイルに名前をつけて、拡張子をbatとして保存します。フォルダはプロジェクトと同じところに入れておくのが無難です。

(2)アクションを次のように設定する。
下のほうにある欄で設定をします。”タイプ”は一般、”名前”は表示のためだけなので日本語でも大丈夫です。アクションのところにはさきほど指定したバッチファイルの場所を入力します。そのあとスペースをはさんで画像の場所を記入したカラムを示します。アクションの欄の下にあるポップアップで選んでから”フィールドを挿入”とします。最後に忘れず”アクションリストへ追加”をクリックします。

上記によってアクションリストに下記が加わりました。OKを押して通常の画面に戻ると、下図で地物アクションの実行というアイコンのポップアップに上記アクションが追加されるはずです。ここでアクションを選んだら、あとはそれぞれの地物をクリックすると画像が開くはずです。(OSMをベースマップにしています。)

バッチファイルを使わなくてもできるようですが、私は今のところうまくいっていません。画像を開くとき、一瞬バッチファイルが開くのがうっとおしいかもしれませんが、とりあえず目標は達成しました。
Rでヒストグラムをつくる
ヒストグラムは統計の授業でも最初のほうに出てくる基本的なグラフですが、Excelでつくろうとするとアドインを加えたり、区間を定義したりとちょっと面倒です。Rだとかなり簡便に作れます。
1)データの読み込み
csvファイルを読み込ませる方法もありますが、ウェブで調べてみるとコピペでデータを読み込ませる方法があり、これがたぶん一番簡単ではないかと思いました。まず、ヒストグラムをつくりたいデータをコピーします。Excel上に入力してあるときはデータ範囲をドラッグしてコピーです。次に、Rのコンソール画面で次のように入力します。
>A=scan("clipboard")
これでEnterを押すと、さきほどのデータが読み込まれます。たとえば140個のデータなら、
Read 140 items
などと返されるでしょう。Aというのはデータセットに名前をつける便宜的なものなので"D"でも"S12"でも"Money"でもなんでもよいです。
2)ヒストグラムの作成
> hist(A)
とするともうヒストグラムが表示されるはずです。
3)区間の変更
デフォルトで設定されている区間でなく指定したい場合は次のように調整します。
> hist(A,breaks=seq(0,10,0.5))
これは0から10までの範囲で0.5ずつの区切りでデータを分けたヒストグラムを作成せよという意味になります。
4)データの重ね合わせ
別のデータを上記ヒストグラムに重ねるときは、まず別のデータセットを読み込んでおきます。上記1と同様にコピペです。
>B=scan("clipboard")
つぎにBのヒストグラムを重ねわせるには、
> hist(A,breaks=seq(0,10,0.5))
> hist(B,breaks=seq(0,10,0.5),col="#808080",add=T)
とします。col="...."は色指定をするコマンドで、色のコードは6ケタで与えます。このコードは次のサイトを参考にしてください。add=Tが先にできたヒストグラムに新たなヒストグラムを重ね合わせるコマンドです。
y軸がおさまらないときは、上記コマンドの中にylim=c(0,100)等と入れます。y軸の範囲が0から100までという意味です。たとえば次のように書きます。
> hist(A,breaks=seq(0,10,0.5),ylim=c(0,100))
CONTAXレンズを使ってみました
フィルムカメラの時代はもうすっかり過ぎ去った感があります。私は10年ほど前にフィルムカメラNikon FM3Aを購入しましたが、今となってはほとんど使用していません。代わってもっぱら使用しているのはOLYMPUSのデジタル一眼レフカメラE-3です。耐久性も高くて機能も申し分ない良いカメラです。しかし、レンズには不満がありました。もちろんOLYMPUSの純正レンズにも良いものはあるのですが、デジタル対応はけっこう良い値段がします。一方、フィルムカメラ用のレンズは中古市場でどんどん値下がりしてきました。そんなわけで、今回中古でCONTAXのTele-Tessar(テレテッサー) T*300mm F4 MM というレンズを購入しました。光学系はツァイス社製で、なんと発売時は21万円の値がついていたこのレンズが、今回3万円台で購入できました!もちろんアダプターをかまさなければOLYMPUS E-3のフォーサーズマウントには使えませんし、ピントも露出もマニュアルです。きっとデジタル世代には考えられないことでしょうが、30年以上前からフィルムカメラを使っていた身には懐かしい感覚です。もちろん動き回る被写体は不利ですが、あわせたいところにピントをもってくるとか、露出を自身の希望でこきざみに変えるにはかえって楽なくらいです。しかもカメラはデジタルなので結果は確認できる(笑)。かつては現像結果をドキドキしながら見たものですが、そのドキドキ感は良い思い出として、デジカメで確認できることによって実はマニュアルレンズはけっこう使えます。撮影した4つの写真を添付しました。シャープさと上品さを兼ね備えている印象です。1kg近くとそれなりに重いですが、シャッタースピードに気をつければ手持ちは十分可能です。



